这一篇论文对深度学习有重大意义。因为这一篇论文的成功,使得深度学习成为‘潮流’。它首先将卷积神经网络应用于Imagenet比赛,并获得当年该比赛第一名。
摘要
作者训练了一个深度卷积神经网络,去分类120万、1000类高分辨率图片。在测试数据上,取得了37.5%top-1错误率和17.0%top-5错误率(top-1错误率就是预测第一个结果错误的比例,top-5错误率就是预测前五个结果错误的比例),作者使用深度卷积神经网络包含6千万个参数、650000个神经元、五层卷积和池化、三层全连接。为了防止过拟合,作者在训练的时候使用了Dropout。
主要内容
The Architecture
论文中给出的网络结构设计。作者还说明了,他认为网络架构上比较新奇的特征,我会就这几点做详细说明。
ReLU Nonlinearity
传统的激活函数是,它是线性的,将输入映射到(-1,1)之间,而Relu是,它是非线性的,相比于tanh,它计算更简单。作者指出,在CIFAR上达到相同error情况下,Relu激活比tanh激活快六倍。
Training on Multiple GPUs
作者使用多个GPU训练模型,主要是提高训练效率,这一点是受限于当时算力的无奈之举。分布式训练的思路可以在网络架构中看出来。这一点不多说。
Local Response Normalization
前面提到过,tanh将输入映射到(-1,1),相当于一个归一化操作,这具有很好的性质(具体有什么,我现在还说不清楚),但是Relu激活没有这一性质,因此作者提出了LRN,局部响应规整,对Relu的输出做一些约束。公式如下:
表示第i个卷积核输出中点(x,y)的值,N为卷积核的总数,n代表使用多少层卷积核的输出来规整,k,,,为经验参数。现在来简单理解一下这个公式的意思,假设有一张图片,224*224*3经过5*5*64的卷积核处理,并使用paddding保持卷积处理后尺寸不变,那么得到224*224*64,此时N=64,若n=3,对于224*224*i层,使用224*224*(i-1),224*224*i,224*224*(i+1)对224*224*i层中每一个(x,y)进行规整。为了防止越界,求和的上下限都使用max和min进行约束。这有一个很好理解的例子。
Overlapping Pooling
我认为池化一般用来降维,消除信息冗杂。阅读UFTDL(tutorial中关于静态性的解释,我不是很理解,大家有见解的可以私信给我),可以了解池化这一操作以及原理,一般池化是不重叠的,作者在文中提出一个重叠的池化操作,降低了错误率,作者观察到这样做,模型更难过拟合。真的是这样吗?我觉得可能只是效果好而已。
Overall Architecture
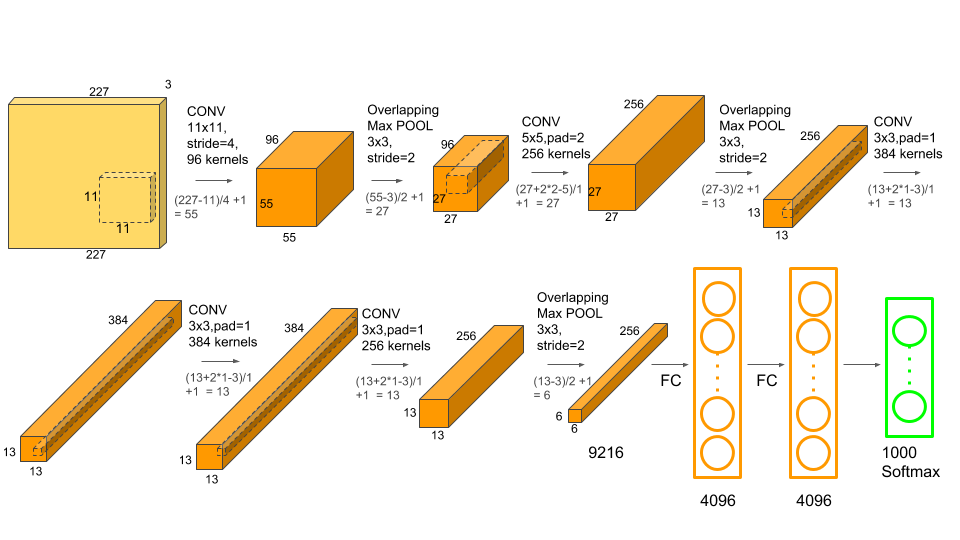
作者在论文中说输入图片为224*224*3,经过11*11*48卷积处理后,输出55*55*48,根据,可知这个结果有问题,因此输入图片应该为227*227*3。模型由卷积、最大池化、全连接组成,特别是把网络分成两部分训练,充分利用GPU。
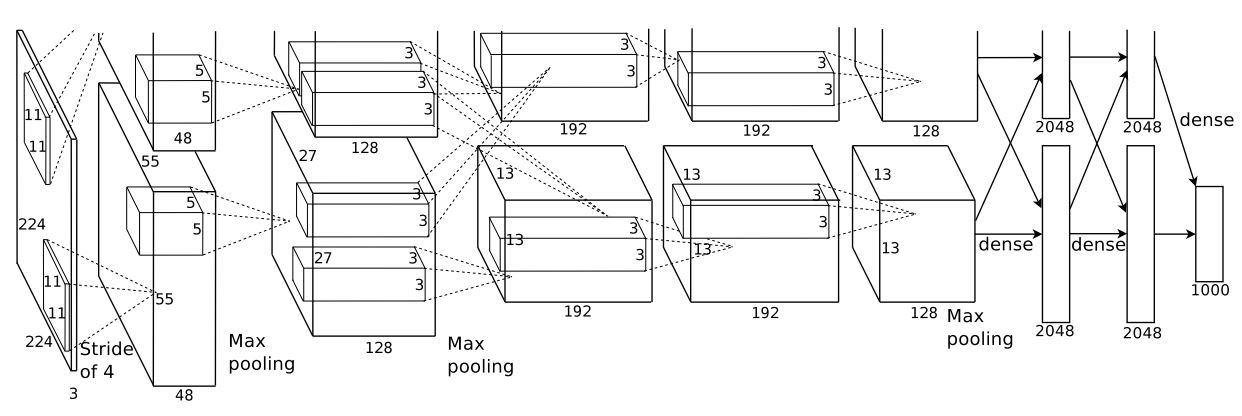
来算一下,网络的参数,第一层卷积参数(11*11*3*48+48)*2=34944,第二层卷积参数(5*5*128+128)*2=307456,第三层卷积参数(3*3*128*192+192)*4=885504,第四层卷积参数(3*3*192*192+192)*2=663936,第五层卷积核参数(3*3*192*128+128)*2=442624,第六层全连接(6*6*128*2048+1)*4=37748740,第七层全连接(2048*2048+2048)*4=16777220,第八层全连接(2048*1000+1000)*2=4096002,总共60963612,其中卷积核参数2331464,占总参数3.8%。因此想要减少参数,需要减少全连接的参数,这是后续研究的突破点。
最后,将结构图转化一下方便理解,但是参数计算,还是得按照原图,因为它两个分支不是互相连接的,只有第三层卷积是互相连接,其它都是彼此分开的。
Reducing Overfitting
Data Augmentation
文中用了两种形式的数据增强,第一种形式的数据增强包括生成图像平移和水平反射。原始图片尺寸为256*256,随机裁剪227*227构成新的图片,并通过水平反射生成新的图片,通过这两种方法使数据集扩大2048。在测试阶段,对测试图片的四个角和中央进行裁剪,得到五张图片,对这五张图片的预测结果进行平均。


第二种形式的数据增强是图像色彩强度变换,对于ImageNet中的图像,将每一个像素点视作三维向量,使用PCA提取主成分,然后得到一个3*3的协方差矩阵和为特征向量和特征值,然后对图片的每一个像素,加一个随机扰动,其中为(0,0.1)的正太分布,这样处理使错误率下降1%。这一点我不是很明白,我不知道PCA处理后的结果是什么,怎样得到协方差矩阵?你可以参看key-deep-learning-architectures-alexnet,理解一下。
Dropout
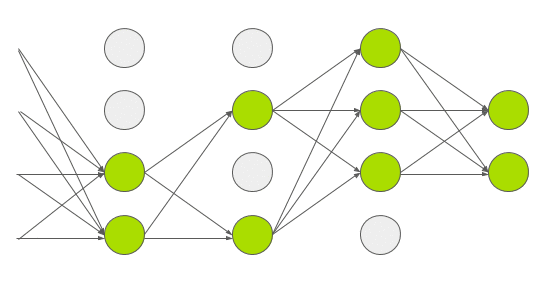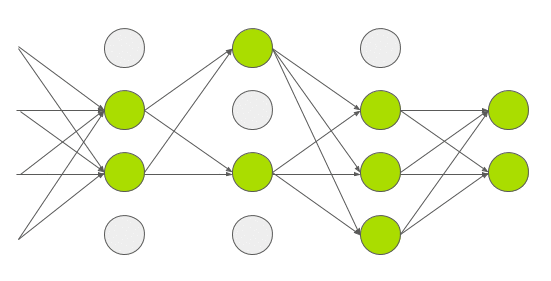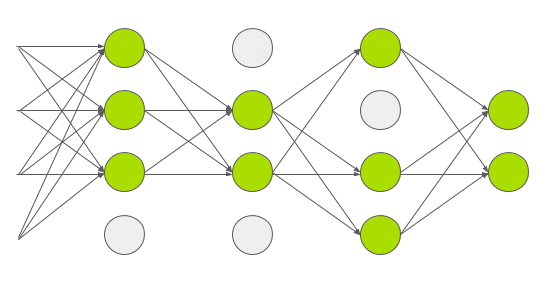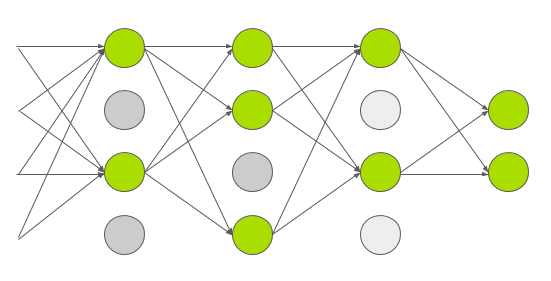
这是Hinton的另一篇文章中提到的方法,也是目前经常用于防止过拟合的办法。在训练阶段,随机’drop’部分神经元,如下图,这能防止,同时会使迭代次数变多。对于dropout,等后续读了Hinton的文章,会补充更详细的理论。
总结
这篇文章的网络结构比较简单,但是参数达到了六千万。这给后续工作提供了一些方向,一是更复杂的网络,二是更少的参数,后续总结会逐渐涉及。另外,这篇文章提供两个提高准确率的trick–数据增强和模型融合(这两个trick也许不是这篇文章先提出了),我觉得数据增强就是想办法扩大数据集,还有点意义。而模型融合我觉得就是为了刷榜,没啥意义,融一堆模型,效果是好,但是没办法应用,个人认为就应该规定单模型。
Reference
- ImageNet Classification with Deep Convolutional Neural Networks by Alex Krizhevsky, Ilya Sutskever, and Geoffrey E. Hinton, 2012
- http://ufldl.stanford.edu/tutorial/
- https://www.learnopencv.com/understanding-alexnet/
- https://medium.com/@pechyonkin/key-deep-learning-architectures-alexnet-30bf607595f1