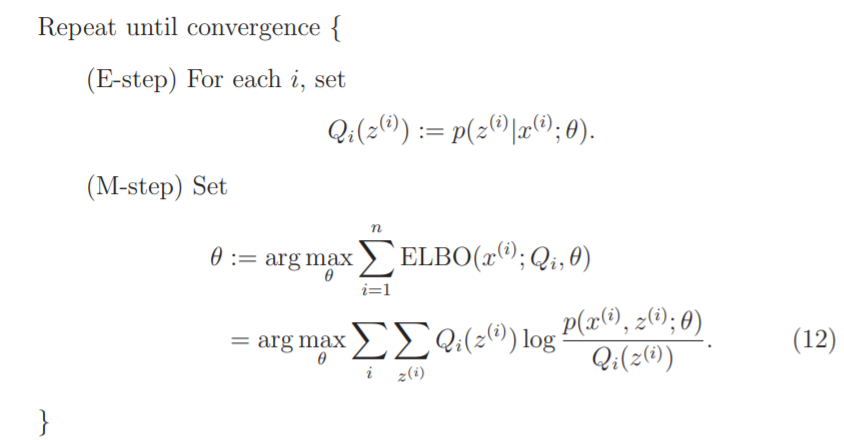上一篇EM算法中提到了李航的统计学习方法,但是没有说明书中的公式推导和Andrew Ng的区别,本文先说明两者的异同点,再说明怎样计算GMM模型和参数计算。如果你看懂了EM算法的原理,GMM模型就很好理解。但是我菜,我不会矩阵求导,式子列出来了,我解不出来,看了半天资料,才勉强看懂。
EM算法(李航统计学习方法版本)
面对一个含有隐变量的概率模型,目标是极大化观测数据(不完全数据)Y关于参数$\theta$的对数似然函数,及最大化:
有人可能有疑问,为什么这个式子和Andrew Ng推导的式子不同。其实是一样的,只不过,他这里没将$Y$展开,$Y$代表整个样本集。接下来的推导思路就不同了。
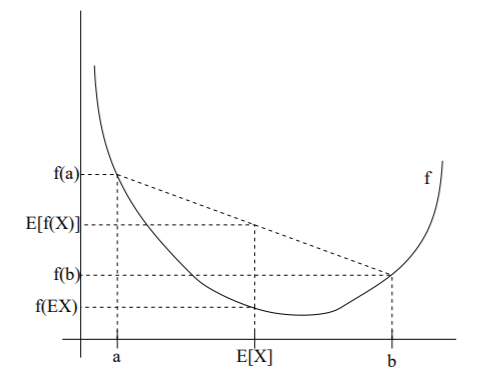
因为我们要通过迭代逐步极大化,假设在第i次迭代后的估计值是,我们希望新的估计值能使增加,即,并逐步达到极大值,为此,我们考虑两者的差:
利用Jensen不等式得到其下界:
| 令:$$B(\theta, \theta^{(i)})=L(\theta^{(i)})+\sum_Z P(Z | Y,\theta^{(i)})log \frac{P(Y | Z,\theta)P(Z | \theta)}{P(Z | Y,\theta^{(i)})P(Y | \theta^{(i)})} \tag{4}$$ |
则有:
即是的一个下界,而且由式知道。将替换成 ,将条件概率展开,就能知道分母和分子相同,也就是说这个式子等于1。
因此,任何可以使增大的,也可以式增大。也就是说选择使达到极大,即:
现在来求的表达式:
书中对函数的定义和Andrew Ng的定义有些不同。后者的定义是隐含变量的后验概率,它是后者函数的一部分。我参看华校专《python大战机器学习》中的定义,它的物理意义是:完全数据的对数似然函数关于某个分布的期望。该分布就是 的真实条件概率的一个近似,由给出。再来分析一下最后求解的表达式,将Andrew Ng的式子中分母的函数(因为确定,Q函数就确定了),两者就是相同的。最后,我给出算法流程:
Repeat until convergence{
(E-step)for dataset Y, set:
(M-step)Set:
}
总的来说,两个思路是差不多的,都是想办法极大化似然函数,巧妙的运用了Jensen不等式,不同就是函数的定义,我目前也不知道那种被公认,或者两者都是自己定义的,没有一个公认的说法。
GMM模型(高斯混合模型)
我们有训练集,现在需要对训练集聚类,聚类是无监督学习,因此不需要标签。我们假设训练集的数据服从联合高斯分布,这个假设是合理的,因为自然中的数据大多符合高斯分布。现在我们来建模:
其中代表高斯混合成分,即训练集由高斯分布组合而成,代表高斯分布的权重;代表高斯分布密度, ,即代表高斯分布均值和协方差。一维高斯分布到多维高斯分布的理解,参考jermmy。
我们来理解一下数据产生的过程,首先依概率选择第k个高斯分布分模型 ;然后依第k个分模型的概率分布生成观测数据。理解了数据产生过程后,我们要找出隐含变量,观测数据是已知的,但是观测数据来自哪个分模型是未知的,我们假设隐含变量为,定义如下:
是0-1随机变量,它为1的概率就是后验概率。接下来,我们来推导参数更新的式子,这里我按照Andrew Ng的算法流程来推导,因为我觉得他思路的比较清晰,先求隐变量的后验概率,再最大化似然函数,而李航的书中,是直接求似然函数,再最大化。
E步:
又有:
M步:
现在我们对上式求导,来解出,我们一步步求导(靠,这公式真的难敲),建议先看一下长躯鬼侠的矩阵求导术,特别是例四例五。好了,我相信你看懂了,我就不求导了,太难了。我给出最后结果:
只需要对求导就可以了,需要引入拉格朗日乘子来解决,参考Andrew Ng。另外注意到, 式中是,它这里采用了贪心的策略来极大化似然函数。
如果你看过李航统计学习方法和Andrew Ng的资料的话,你看能会想和之间有什么区别,其实它们是一样的。先来看看它们各自的意义,前者是的期望,后者是属于第$k$个分模型的概率,由于是0-1分布,这个概率就是期望。
GMM模型的应用
这里我主要说一下,它在说话人识别中的应用,代码可参见github。对于语音材料,我们首先预处理,分帧、预加重,然后提取语音特征,常用的MFCC特征,一帧语音提取13维特征。对于每一个人,我们都有了大量的数据。然后,我们对每一个人训练一个GMM模型,有n个人,就有n个模型,模型的高斯混合成分由valid数据集确定。测试阶段,对于一个新的语音,我们将它代入每一个模型,都会得到一个后验概率,概率越大,表示这段语音属于这个人的概率越大。
其中不用求解,是均匀分布,因此先验概率的大小就代表了后验概率的大小。
总结
本篇博客,先说明了李航统计学习方法中EM算法,比较了两者的异同。后又利用EM算法求解GMM模型的参数。后续,我会用python写一套代码求解GMM模型,有兴趣的话可以先参考medium和huangyc
Reference
https://towardsdatascience.com/gaussian-mixture-modelling-gmm-833c88587c7f https://www.cnblogs.com/huangyc/p/10274881.html https://zhuanlan.zhihu.com/p/24709748 http://cs229.stanford.edu/notes-spring2019/cs229-notes8-2.pdf 李航:统计学习方法 华校专:python大战机器学习